Kinesis Tuning for Low Latency
Kinesis is a big fat pipe, lots of records go in one end, and come out the other in big chunks.

I'm the architect of the 3t platform. I've been building scalable platforms for over 25 years and I'm here at 3t digital making event driven microservices in AWS so that clients like yourself can have a hassle free, fast and reliable experience when you use our platform for competency and compliance.
Goal
To keep the data flowing as real-time as possible, while at the same time not costing the earth.
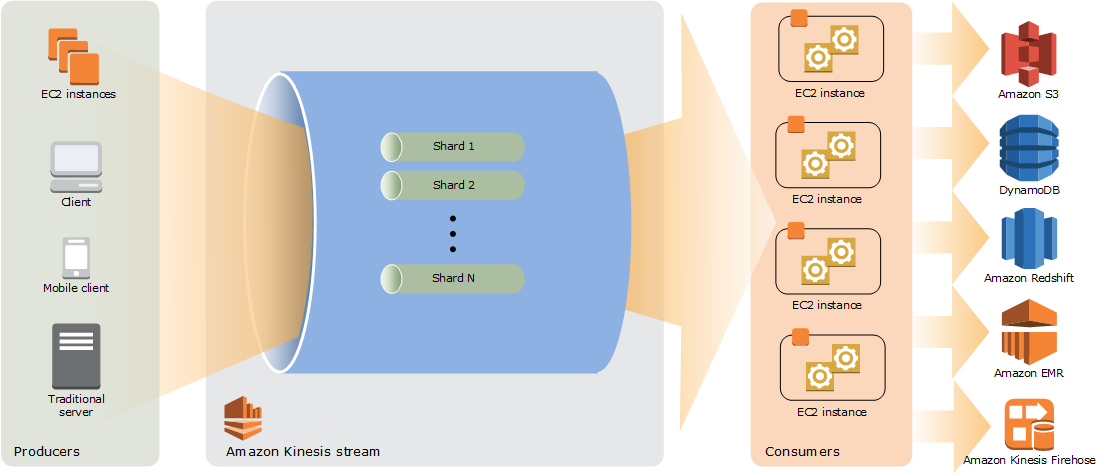
Yes, Kinesis is a big fat pipe, lots of records go in one end, and come out the other in big chunks.
Kinesis Described With a Delicious Metaphor
AWS Kinesis is a data streaming service that allows you to collect and process large amounts of data in real-time.
Imagine you work at a chocolate bar factory, and you have a conveyor belt that brings in all the ingredients for the chocolate bars (cocoa, sugar, etc.). As the ingredients come in, you need to quickly sort and process them, so they can be turned into delicious chocolate bars.
AWS Kinesis is like having a team of workers stationed along the conveyor belt, each with a specific job to do. One worker might be responsible for sorting the cocoa beans, another for measuring the sugar, and so on. Each worker takes their specific task and passes it on to the next worker, who then performs their own task, and so on, until the ingredients are ready to be turned into chocolate bars.
Similarly, AWS Kinesis allows you to set up a stream of data from various sources (such as website clicks or IoT sensors) and process it in real-time. You can use Kinesis to sort, filter, and analyze the data as it comes in, so you can quickly make decisions based on the information you're receiving. Just like the workers along the conveyor belt, Kinesis helps you turn raw ingredients into a finished product, in this case, valuable insights that can help you make informed decisions for your business.
In addition to processing the ingredients as they come in, the workers along the conveyor belt need to package them into boxes, so they can be shipped out to stores. Instead of packaging each chocolate bar individually, they group them together into batches of a certain size, such as 10 bars per box.
Similarly, with AWS Kinesis, you can configure the service to batch data together before it's processed or analyzed. This can help reduce costs and improve performance, since it's often more efficient to process data in batches rather than one piece at a time.
For example, let's say you're collecting data from IoT sensors that are sending temperature readings every second. Instead of processing each individual reading as it comes in, you could use Kinesis to batch the readings together into groups of, say, 10 readings at a time. This way, you can analyze the data as a group and make decisions based on trends or patterns in the data, rather than reacting to every single reading.
Once the data has been processed or analyzed, just like the chocolate bars, you'll want to package it up and send it out to where it needs to go. In the case of Kinesis, you might send the data to other AWS services like Amazon S3 or Redshift for storage, or to Amazon Lambda for further processing. By batching and packaging the data in this way, you can streamline your data pipeline and make it more efficient.
Data Streams and Firehose?
Kinesis Data Streams can be thought of as the workers stationed along the conveyor belt who are responsible for processing the raw ingredients (data) as they come in. Just like the workers, Kinesis Data Streams allows you to process and analyze streaming data in real-time, and enables you to create custom applications that can consume and process data from multiple sources.
In the chocolate bar factory, the workers along the conveyor belt might use specialized tools or machines to help them sort and process the ingredients more efficiently. Similarly, with Kinesis Data Streams, you can use custom applications or tools (such as AWS Lambda functions) to process and analyze the data in real-time, and then send the results to other AWS services or applications.
On the other hand, Kinesis Firehose can be thought of as the boxes that are filled with finished chocolate bars and sent out to stores for sale. Instead of processing and analyzing the data, Kinesis Firehose is designed to help you efficiently and reliably load streaming data into other AWS services for storage, analytics, and further processing.
In the chocolate bar factory metaphor, Kinesis Firehose might represent a conveyor belt that takes the finished chocolate bars and packages them into boxes for shipment. Similarly, with Kinesis Firehose, you can configure the service to automatically load streaming data into other AWS services such as Amazon S3, Redshift, or Elasticsearch, making it easy to store and analyze your data in a scalable and cost-effective way.
Batching and Kinesis
The BatchWindow and BatchSize properties are used to configure the batch processing behavior of a Lambda function (for exmaple) that is triggered by an Amazon Kinesis Data Stream.
batchWindow: This property specifies the maximum amount of time in seconds that Lambda waits before triggering a batch of records. If the batch window is set to 1 second, for example, Lambda waits up to 1 second before triggering a batch of records, even if the batch size has not been reached. If a batch of records is triggered before the batch window expires, Lambda resets the timer and starts waiting again.
batchSize: This property specifies the maximum number of records to include in each batch. If the batch size is set to 100, for example, Lambda triggers a batch of up to 100 records, even if the batch window has not expired. If there are fewer than 100 records available in the stream, Lambda waits until the batch window expires before triggering the batch.
By configuring the batch window and batch size, you can control the trade-off between processing speed and resource utilization in your Lambda function. A smaller batch window and batch size can reduce the latency of processing individual records, but may result in higher resource utilization due to more frequent Lambda invocations. A larger batch window and batch size can reduce the frequency of Lambda invocations, but may result in higher latency for individual records.
It's important to note that the batch window and batch size are interrelated, and changing one may require adjusting the other to achieve optimal performance. Additionally, the batch window and batch size should be chosen based on the characteristics of your Kinesis data stream, such as the rate of incoming records and the processing requirements of your Lambda function.
💡 Lower numbers here for both of these equal lower latency. Larger numbers will be cheaper but add more latency.
Optimise your Target
When Kinesis hands off a batch to a Lambda, the speed of the Lambda is important to get the data to its destination. Let's talk about some of the ways we can do that.
Though beyond the scope of this article, it stands to reason that the response time and time spent processing in the Lambda you may point your stream towards would be better if it was very (very) short. Here are a few articles to get your Lambda lean:
Lambda Performance: AWS Lambda Performance Tuning & Best Practices (2023)
AWS Lambda Benchmark: GitHub - theam/aws-lambda-benchmark: A project that contains AWS Lambda function implementations for several runtimes e.g. Nodejs, Haskell, Python, Go, Rust, Java, etc.
Here is a table from the AWS Lambda Benchmark repo with some previously collected data (You may need to run your own tests to see the most recent results). You will notice that cold starts come into play here for very low stream saturation, but we are assuming that since you are using Kinesis that this is a high invocation situation. Looking at this table it is clear to see that we can get the best performance from certain runtimes, Go in particular looks appealing here, please experiment if this is something you are trying to optimise. Remember that this table represents a 'hello world' example and will not include any processing, these are the minimum times, not your times.
| Runtime | Best Cold Start | Worst Cold Start | execution time | Max memory used |
| Haskell | 60.30 ms | 98.38 ms | 0.86 ms | 48 MB |
| Java | 790 ms | 812 ms | 0.89 ms | 109 MB |
| Nodejs | 3.85 ms | 43.8 ms | 0.26 ms | 66 MB |
| Go | 1.39 ms | 7.60 ms | 0.25 ms | 48 MB |
| Rust | 39.1 ms | 58.7 ms | 0.70 ms | 34 MB |
| Python | 15.9 ms | 33.2 ms | 0.22 ms | 50 MB |
| Ruby | 11.5 ms | -- | 1.42 ms | 51 MB |
| C# .NET 2.1 | 631 ms | -- | 0.17 ms | 83 MB |
| F# .NET 2.1 | 528 ms | -- | 0.22 ms | 84 MB |
Minimize package size
Lambda functions have a maximum deployment package size of 250 MB, and larger packages can slow down function deployment and execution. To optimise your Lambda function for faster processing, you should try to minimize the size of your deployment package by removing unnecessary dependencies and code.
Use caching
Caching frequently accessed data in memory can improve the performance of your Lambda function. For example, if your function needs to make requests to an external API, you could use a caching library like Redis to store the response data in memory, so that subsequent requests can be served faster. Ideally, this data processor should not have to use caching, it needs to be as minimal as possible.
Optimise code for concurrency
Lambda functions can process multiple events concurrently, so it's important to optimise your code to take advantage of this concurrency. For example, you could use asynchronous programming techniques to parallelize tasks within your function or use connection pooling to reduce the overhead of establishing new connections to external services.
Optimise input/output handling
Minimizing the amount of data that your function reads and writes can improve processing speed. For example, you could use binary input and output formats instead of text-based formats to reduce processing overhead or compress your data to reduce the amount of data that needs to be transferred. Consider compression, since the size of the data put into Kinesis also affects its performance, but also consider the decompression cost in the receiving Lambda.
Provisioned Concurrency
Provisioned concurrency is a feature of AWS Lambda that allows you to pre-warm your function with a specified number of instances so that when an event arrives, there are already enough warm instances to handle the request without any cold starts.
In Lambda, cold starts occur when a new instance of your function needs to be initialized to handle an incoming event. This initialization process includes loading dependencies and setting up the execution environment, which can take several seconds and result in increased latency for the first request. This can be particularly problematic for applications with strict latency requirements, such as real-time data processing or web applications.
Provisioned concurrency can help reduce the impact of cold starts by pre-warming your function with a specified number of instances. This means that there are already enough warm instances available to handle incoming requests, which eliminates the need for new instances to be initialized and reduces latency for the first request.
Conclusion
When it comes to using AWS Kinesis, it's important to understand the trade-offs between speed and cost and to optimise your usage accordingly. Batching is generally better for storage, as it can help reduce costs and improve performance. However, if you need real-time processing and analysis, you may need to sacrifice some cost optimization for faster processing.
Keep in mind that many other factors can influence the efficiency of processing with Kinesis, such as package size, runtime environment, caching, and input/output handling. By experimenting with different optimization techniques and tuning your Kinesis configuration to meet your specific needs, you can achieve the best possible performance and cost-effectiveness for your use case.