The Event Lifecycle of Microservices
Let's explore the events a service might work with to be a good citizen in an event-driven microservice architecture.

I'm the architect of the 3t platform. I've been building scalable platforms for over 25 years and I'm here at 3t digital making event driven microservices in AWS so that clients like yourself can have a hassle free, fast and reliable experience when you use our platform for competency and compliance.
TL;DR
If you are querying data directly without events and something happens, throw an error in the service for your monitoring solution to catch and return something useful to the caller.
If your service is event-driven, then follow the event lifecycle. Emit errors when something goes wrong.
In a microservice architecture with an event bus, errors can be handled in a few different ways. One approach is to use a dead letter queue (DLQ) for events that cannot be processed successfully. The DLQ can be monitored and messages can be replayed or handled manually. Another approach is to use a circuit breaker pattern to temporarily halt the processing of messages if errors occur at a high rate. This can prevent cascading failures and allow the system to recover more quickly. Additionally, you can implement retries and exponential backoff mechanisms to handle transient errors.
Another approach is to use a monitoring solution to keep track of the service's health, such as its error rate, response time, and other relevant metrics. This enables us to detect issues early and take corrective actions before they become critical. It is important to have proper logging and tracing in place to be able to diagnose and debug errors when they do occur.
Let's explore the events a service might work with to be a good citizen in an event-driven microservice architecture.
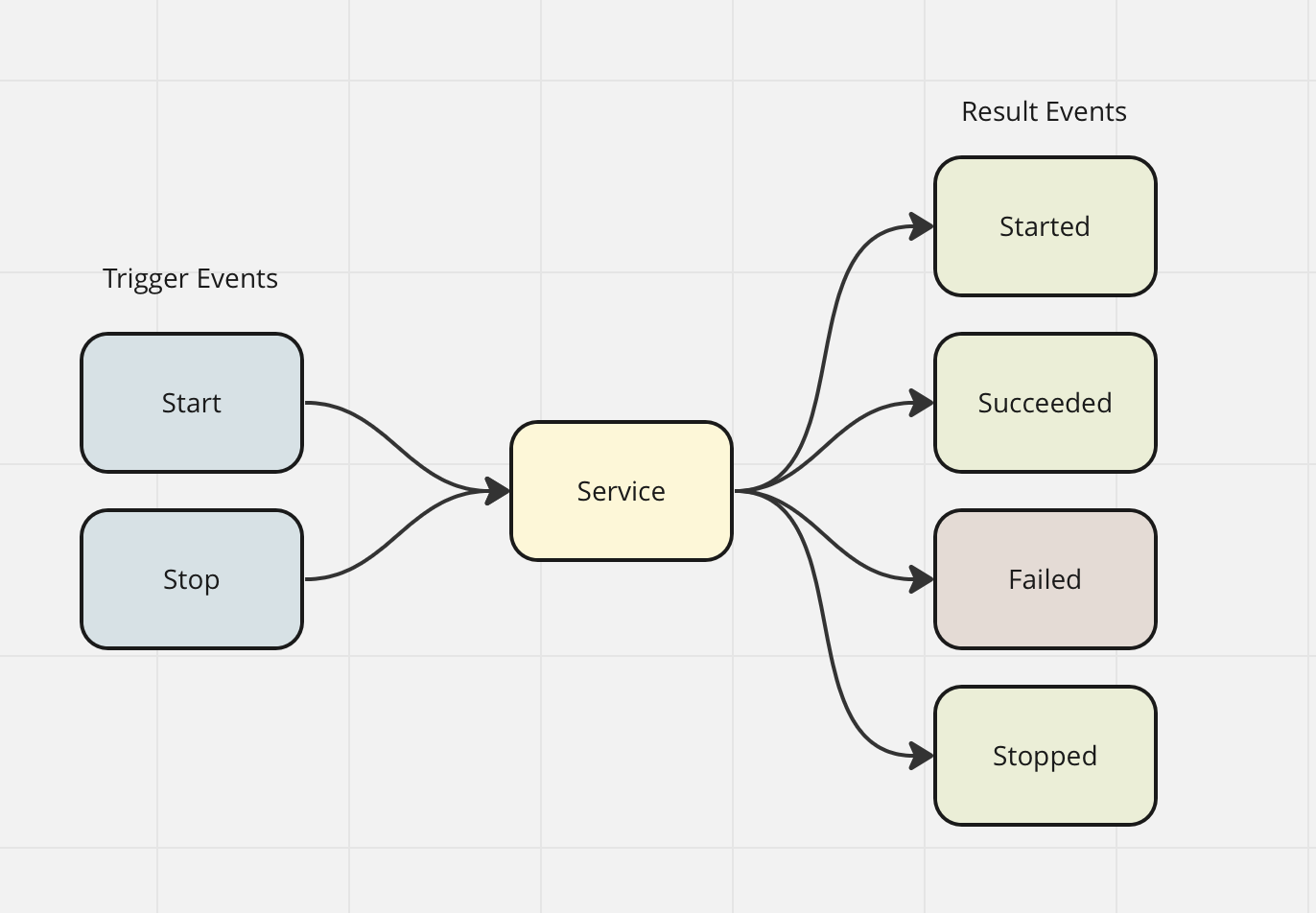
A (Possible) Lifecycle of Actions
(Trigger) Magical Data Sync Start
(Trigger) Magical Data Sync Stop
Magical Data Sync Started
Magical Data Sync Succeeded
Magical Data Sync Failed
Magical Data Sync Stopped
In this example, we have a service that may have a long-running process. The process is calling a third-party API and processing the response. The sync is not instant and requires long-running, time-consuming computing. This process will be triggered by an event.
Magical Data Sync Start
This event can be emitted by any service that would like to interact with the Magical Data Sync Service. This will contain enough information in its detailed payload to instruct the service to start processing its data, magically. It is a smart move to create a UUID and send this into the service. This way, as the service emits events related to your trigger, you can track them and know which ones are related to this initial trigger.
Magical Data Sync Started
This event is emitted by the Magical Data Sync service. It signifies that the service has received the message and is starting its sync. This is a good event to assert that the contract is correct in the sending service since it should only trigger if the service has accepted the start event and everything in the payload is correct. This event might contain the triggering ID so that anything listening to the events can track a single job.
Magical Data Sync Succeeded
This event is emitted by the Magical Data Sync service. It happens when the work is complete. As is good practice, if the data is small enough to fit into a single event, then return the result of the service run here. It is unwise to include only a link to data you would otherwise include in the success event because you are forcing the receiver of this event to look up data in another service, an antipattern. The exception to this is of course if large files are downloaded, or content that can not be represented as text, such as zip files or images.
Magical Data Sync Failed
This event is emitted by the Magical Data Sync service. It can happen for any number of reasons, but the data we include here is clear. Include the reason this service failed in the event. Developers of this service will use this event in their integration testing to assert the service is behaving as expected, by testing the red paths. Consumers of this service will use it to determine if their input into the service is sound and that the service is behaving itself.
Controllable Jobs
Adding to this basic set of events a service can emit, if this service has long-running tasks that we can control, there are two more events we need to talk about:
Magical Data Sync Stop
This event can be emitted by any service that would like to interact with the Magical Data Sync Service. It can be used to prematurely end a long-running process, possibly to save resources. This is common if you want to process a similar item that supersedes the one that is already running, for example, requesting conversion of a new video file that was re-edited, making the currently processing video obsolete.
Magical Data Sync Stopped
This event is emitted by the Magical Data Sync service. It is a type of success state since it describes that your request to stop a currently running process has been stopped correctly. If you are feeling generous, you may return information here about the incomplete task.
Events as Errors
It can be useful to emit errors as events in a microservice architecture with an event bus. Events from a service can be errors, they can be tracked, logged, and analyzed in a centralized manner. This can help understand the causes of errors and identify patterns or trends that may indicate a larger problem.
Emitting errors as events allow you to build specific error-handling microservices that subscribe to these events and take action on them, such as sending notifications, triggering a rollback, or other recovery steps.
As a strong example, if we build a webhook service that allows the client to call their system and POST data to it, we want to know about each error the service has encountered because the end user will want to see the HTTP logs so that they can attempt to diagnose why their POST endpoint is not working correctly. This means the 'Webhook Call Failed' error event will need to be stored, and we can write a decoupled service that does this, for later display to the end user.
Do:
Emit 'Failed' events when they occur, to centralize error tracking and logging.
Use clear and descriptive event names to make it easy to identify the source of the error.
Include relevant information in the event payload such as the error message, stack trace, and context.
Create a JSON schema contract for every event your service emits, error or otherwise.
Use error events to trigger automated recovery actions such as rolling back a transaction, deleting a half-finished file or sending a notification.
Don't:
Do not emit error events if it's possible to return an error to the user straight away, for example, if a GET call invokes a Lambda for a REST service. In this case, throw an error in the service for CloudWatch logging to do its job.
Do not include sensitive information in error events, such as user passwords or personal data.
Do not use generic event names such as "error" or "exception". Use specific names that accurately describe the error to help the debugging process should something go wrong.